
tl;dr
At GTC 2024 representing over $100 trillion in global industries, the focus shifted from reducing computing costs to exponentially increasing computing scales. This paradigm shift is dubbed “generation” rather than “inference,” signaling a move away from traditional data retrieval methods towards generating intelligent outputs. The discussion highlighted the ongoing industrial revolution in artificial intelligence, where even complex entities like proteins, genes, and brain waves are being digitized and understood through AI, leading to the creation of their digital twins.
The keynote stressed the transformation of AI applications, citing the AI Foundry’s three main components: NIM, NeMo Microservices, and DGX Cloud. These tools underscore a new era where both structured and unstructured data is converted into a dynamic AI database. This database not only stores information but interacts intelligently with users, marking a significant evolution from traditional semantic encoding to a world where meaning is embedded in digitally generated scenes.
Contents
My Study Notes
Opening
Opening Video
- [music]

- I am a Visionary, Illuminating galaxies to witness the birth of stars, and sharpening our understanding of extreme weather events.

- I am a helper, guiding the blind through a crowded world.
- I was thinking about running to the store.
- and giving voice to those who cannot speak.
- to not make me laugh.
- I am a Transformer, harnessing gravity to store renewable power, and paving the way towards unlimited clean energy for us all.

- I am a trainer, teaching robots to assist to watch out for danger and help save lives.

- I am a Healer, providing a new generation of cures and new levels of patient care doctor that I am allergic to penicillin.
- is it still okay to take the medications?
- definitely these antibiotics don’t contain penicillin so it’s perfectly safe for you to take them.
- I am a navigator, generating virtual scenarios to let us safely explore the real world and understand every decision.

- I even helped write the script breathe life into the words.

- I am AI, brought to life by NVIDIA deep learning and brilliant minds, everywhere.

NVIDIA founder and CEO Jensen Huang
- please welcome to the stage, NVIDIA founder and CEO Jensen Huang.
- welcome to GTC.

A Developer Conference, Not A Concert
- I hope you realize this is not a concert.
- you have arrived at a developers conference.
- there will be a lot of science described , algorithms, computer architecture, mathematics.
- I sensed a very heavy weight in the room, all of a sudden, almost like you were in the wrong place.
- no conference in the world is there a great assembly of researchers from such diverse fields of science from climatech to radio sciences, trying to figure out how to use AI to robotically control MIMO 1 for next generation 6G radios, robotic self-driving cars, even artificial intelligence.
- everybody’s first I noticed a sense of relief there all of all of a sudden.
- also this conference is represented by some amazing companies.
- this list this is not the attendees.
- these are the presentors.

- and what’s amazing is this.
- if you take away all of my friends, close friends Michael Dell is sitting right there, in the IT industry, all of the friends I grew up with in the industry.

- if you take away that list this is what’s amazing these are the presenters of the non-IT industries, using Accelerated Computing to solve problems that normal computers can’t.

- it’s represented in life sciences, health care, genomics, transportation, of course, retail, logistics, manufacturing, industrial, the gamut of industries represented is truly amazing.
- and you’re not here to attend only, you’re here to present to talk about your research. $100 trillion dollar of the world's industries is represented in this room today.
- this is absolutely amazing.
1️⃣ New Industry - Accelerated Computing
NVIDIA’s Journey and A New Industry
- there is absolutely something happening, there is something going on.
- the industry is being transformed, not just ours.
- because the computer industry, the computer is the single most important instrument of society today.
- fundamental transformations in computing affects every industry, but how did we start, how did we get here, I made a little cartoon for you, literally I drew this.

- in one page this is NVIDIA’s Journey, started in 1993, this might be the rest of the talk.
- 1993 this is our journey, we were founded in 1993, there are several important events that happen along the way.
- I’ll just highlight a few.
- in 2006 CUDA 2 3 which has turned out to have been a revolutionary computing model, we thought it was revolutionary, then it was going to be an overnight success, and almost 20 years later it happened.
- we saw it coming.
- two decades later.
- in 2012 AlexNet 4, AI and CUDA made first contact.
- in 2016 recognizing the importance of this Computing model, we invented a brand new type of computer, we called the DGX-1, 170 teraflops (TFLOP 5) in this supercomputer, eight GPUs connected together, for the very first time.
- (in 2016) I hand delivered the very first DGX-1 to a startup located in San Francisco called OpenAI 6. DGX-1 was the world’s first AI supercomputer.
- (Photo credits: Farhan Hussain)

- remember 170 teraflops.
- 2017, the Transformer 7 arrived.
- 2022 ChatGPT capture the world’s imaginations, have people realize the importance and the capabilities of artificial intelligence.
- and 2023 generative AI emerged, and a new industry begins.
- why, why it’s a new industry?
- because the software never existed before, we are now producing software, using computers to write software, producing software that never existed before, it is a brand new category, it took share from nothing, it’s a brand new category.
- and the way you produce the software, is unlike anything we’ve ever done before.
- in data centers, generating tokens, producing floating point numbers at very large scale, as if in the beginning of this, last industrial revolution, when people realized that you would set up factories, apply energy to it, and this invisible valuable thing called electricity came out, AC generators.
- and 100 years later, 200 years later, we are now creating new types of electrons, tokens, using infrastructure, we call AI factories, to generate this new incredibly valuable thing, called artificial intelligence.

- a new industry has emerged.
Simulation
- well we’re going to talk about many things about this new industry, we’re going to talk about how we’re going to do computing next, we’re going to talk about the type of software that you build, because of this new industry, the new software, how you would think about this new software, what about applications in this new industry, and then maybe what’s next, and how can we start preparing today for what is about to come next.
- well.
- but before I start I want to show you the soul of NVIDIA, the soul of our company, at the intersection of computer graphics, physics, and artificial intelligence.
- all intersecting inside a computer, in Omniverse, in a virtual world simulation, everything we’re going to show you today, literally everything we're going to show you today, is a simulation, not animation.
- it’s only beautiful, because it’s physics, the world is beautiful, it’s only amazing, because it’s being animated with robotics, it’s being animated with artificial intelligence, what you’re about to see all day, it’s completely generated, completely simulated, and omniverse.
- and all of it what you’re about to enjoy is the world’s first concert, where everything is homemade, you’re about to watch some home videos ,so sit back and enjoy yourself.
Home Videos of Omniverse & Digital Twins




- NVIDIA Warp 8


- Cadence Reality Digital Twin Platform 9

- Microsoft PowerBI, Rockwell Automation Emulate3D

- Pegatron

- Amazon Robotics

- NVIDIA NIM - DeepSearch

- SimReady USD

- Siemens Teamcenter X

- Hexagon HxDR

- Audio2Face NIM

- Isaac Perceptor

- BMW Group

- Omniverse Cloud APIs for AV Sim

- Ansys Perceive EM

- God I love NVIDIA.
Accelerated Computing
- Accelerated Computing has reached the tipping point.
- General Purpose Computing has run out of steam, we need another way of doing computing, so that we can continue to scale so that we can continue to drive down the cost of computing, so that we can continue, to consume more and more computing while being sustainable.
- Accelerated Computing is a dramatic speed up over general purpose Computing.
- and in every single industry, we engage and I’ll show you many, the impact is dramatic, but in no industry is a more important than our own, the industry of using simulation tools to create products, in this industry it is not about driving down the cost of computing, it's about driving up the scale of computing.
- we would like to be able to simulate the entire product that we do, completely in full Fidelity, completely digitally, in essentially what we call digital twins.
- we would like to design it, build it, simulate it, operate it, completely digitally.
- in order to do that we need to accelerate an entire industry, and today I would like to announce, that we have some partners who are joining us in this journey, to accelerate their entire ecosystem, so that we can bring the world into Accelerated Computing.
- but there’s a bonus.
- when you become accelerated, your infrastructure is CUDA GPUs, and when that happens, it’s exactly the same infrastructure for generative AI, and so I’m just delighted to announce several very important partnerships, there are some of the most important companies in the world, and Ansys does.

- engineering simulation for what the world makes, we’re partnering with them to CUDA accelerate the Ansys ecosystem, to connect Ansys to the Omniverse digital twin, incredible.
- the thing that’s really great is that the install base of media GPU, accelerated systems are all over the world, in every cloud, in every system, all over enterprises, and so the applications they accelerate, will have a giant installed base to go serve.
- end users will have amazing applications, and of course, system makers and CSPs will have great customer demand.
- Synopsys, Synopsys is NVIDIA’s literally first software partner, they were there in very first day of our company.

- Synopsys revolutionized the chip industry with high level design, we are going to CUDA accelerate synopsys, we’re accelerating computational lithography 10, one of the most important applications that nobody’s ever known about.
- in order to make chips, we have to push lithography to limit.
- NVIDIA has created a library, domain specific library, that accelerates computational lithography, incredibly.
- once we can accelerate and software defined of tsmc, who is announcing today, that they’re going to go into production with NVIDIA cuLitho 11.
- once this software defined and accelerated the next step is to apply generative AI to the future of semiconductor manufacturing, push in geometry even further .
- Cadence builds the world’s essential EDA and SDA 12 tools, we also use Cadence, between these three companies, Ansys, synopsys, and Cadence, we basically build NVIDIA together.

- we are cud accelerating Cadence, they’re also building a supercomputer out of NVIDIA GPUs, so that their customers, could do fluid dynamic simulation at a 100 a thousand times scale, basically a wind tunnel in real time.
- Cadence Millennium 13, a supercomputer with NVIDIA GPUs inside, a software company building supercomputers, I love seeing that, building Cadence co-pilots together, imagine a day, when Cadence, Synopsys, Ansys, tool providers would offer you AI co-pilots, so that we have thousands and thousands of co-pilot assistants, helping us design chips design systems, and we’re also going to connect Cadence digital twin platform to Omniverse, as you could see the trend here, we’re accelerating the world’s Cadence EDA and SDA so that we could create our future in digital twins.
- and we’re going to connect them all to Omniverse, the fundamental operating system for future digital twins.
2️⃣ Bigger GPUs - Blackwell Platform
Size of the models
- one of the industries that benefited tremendously from scale, and you know, you all know this one very well, large language model.
- basically after the Transformer was invented, we were able to scale large language models, at incredible rates, effectively doubling every six months.

- now how is it possible that by doubling every six months, that we have grown the industry, we have grown the computational requirements so far, and the reason for that is quite simply this.
- if you double the size of the model, you double the size of your brain, you need twice as much information to go fill it.
- and so every time you double, your parameter count, you also have to appropriately increase your training token count, the combination of those two numbers, becomes the computation scale you have to support.
- the latest the state-of-the-art OpenAI model, is approximately 1.8 trillion parameters.
- 1.8 trillion parameters required several trillion tokens to go train.
- so so a few trillion parameters on the order of a few trillion tokens on the order of, when you multiply the two of them together approximately 30 40 50 billion quadrillion floating point operations per second.
- now we just have to do some CEO math, right now, just hang hang with me, so you have 30 billion quadrillion.
- a quadrillion is like a petaflop.
- and so if you had a petaflop GPU, you would need 30 billion seconds to go compute, to go train that model.
- 30 billion seconds is approximately 1,000 years.
- well 1,000 years, it’s worth it, like to do it sooner, but it’s worth it, which is usually my answer.
- when most people tell me hey how long, how long’s it going to take to do something, 20 years, how it’s worth it, but can we do it next week, and so 1,000 years, we need, what we need are bigger GPUs, we need much much bigger GPUs, we recognized this early on, and we realized that the answer is to put a whole bunch of GPUs together, and of course innovate a whole bunch of things along the way, like inventing A10 Tensor Cores advancing NVLink so that we could create essentially virtually giant GPUs, and connecting them all together with amazing networks from a company called Mellanox. InfiniBand 14, so that we could create these giant systems, and so DGX-1 was our first version, but it wasn’t the last we built.

- we built supercomputers all the way, all along the way in 2021, we had Selene 15 4500 GPUs or so.
- and then in 2023, we built one of the largest AI supercomputers in the world, it’s just come online, Eos 16.
- and as we’re building these things, we’re trying to help the world build these things, and in order to help the world build these things, we got to build them first.
- we build the chips, the systems, the networking, all of the software necessary to do this, you should see these systems.
- imagine writing a piece of software that runs across the entire system, Distributing the computation across thousands of GPUs, but inside are thousands of smaller GPUs, millions of GPUs to distribute work across all of that, and to balance the workload so that you can get the most Energy Efficiency, the best computation time keep your cost down.
- and so those fundamental Innovations is what got us here.
- and here we are, as we see the miracle of ChatGPT emerg in front of us.
- we also realize, we have a long ways to go, we need even larger models, we’re going to train it with multimodality data, not just text on the internet, but we’re going to we’re going to train it on texts and images and graphs and charts, and just as we learn, watching TV, and so there’s going to be a whole bunch of watching video.
- so that these models can be grounded in physics, understands that an arm doesn’t go through a wall, and so these models would have common sense, by watching a lot of the world’s video, combined with a lot of the world’s languages.
- it’ll use things like synthetic data generation, just as you and I do, when we try to learn, we might use our imagination to simulate how it's going to end up, just as I did when I was preparing for this keynote, I was simulating it all along the way.
- I hope it’s going to turn out as well as I had it in my head.
- as I was simulating how this keynote was going to turn out, somebody did say that another performer did her performance completely on a treadmill, so that she could be in shape to deliver it with full energy, I didn’t do that, if I get a l wind at about 10 minutes into this you know what happened, and so where were we.
- we’re sitting here using synthetic data generation, we’re going to use reinforcement learning, we’re going to practice it in our mind, we’re going to have AI working with AI, training each other, just like student teacher Debaters, all of that is going to increase the size of our model, it’s going to increase the amount of data , that we have and we’re going to have to build even bigger GPUs.
Announcing Blackwell
Announcing Video
- Hopper 17 is fantastic, but we need bigger GPUs.
- and so ladies and gentlemen, I would like to introduce you, to a very very big GPU, named after David Blackwell, mathician, game theorists, probability we thought it was a perfect name.
- Blackwell, ladies and gentlemen, enjoy this.



















- Blackwell is not a chip.
- Blackwell is the name of a platform.
- uh people think we make GPUs, and and we do, but GPUs don’t look the way they used to here.
- if you will the heart of the Blackwell system and this inside the company is not called Blackwell.
- it’s just the number.
- this is Blackwell , most advanced GPU in the world in production today.
- this is Hopper.
- this is Hopper.
- Hopper changed the world.

- this is Blackwell.

- it's okay Hopper, you're very good.
- good.
- good boy, well, good girl.
- 208 billion transistors and so.
- so you could see (I can see) that, there’s a small line between two dies.
- this is the first time two dies have abutted like this together.
- in such a way, that the two dies think it's one chip.

- there’s 10 terabytes of data between it, 10 terabytes per second, so that these two these two sides of the Blackwell Chip have no clue which side they’re on.
- there’s no memory locality issues, no cache issues.
- it’s just one giant chip, and so, uh, when we were told that Blackwell’s ambitions were beyond the limits of physics, uh, the engineer said so what, and so this is what happened.

- and so this is the Blackwell chip.
Two Types of Blackwell Systems
- and it goes into two types of systems.
- the first one is form fit function compatible to Hopper, and so you slide all Hopper, and you push in Blackwell.
- that’s the reason why one of the challenges of ramping is going to be so efficient.
- there are installations of Hoppers all over the world.
- they could be, you know, the same infrastructure, same design, the power the electricity, the thermals, the software, identical push it right back, and so this is a Hopper version for the current HGX configuration.

- and this is what the other the second Hopper looks like this.
- now this is a prototype board, and um, Janine, could I just borrow, ladies and gentlemen, Janine , board, (Janine gave Jensen a huge size PCB board.) and so, this is a fully functioning board.
- and I just be careful.
- here this right here is, I don’t know, 10 billion.
- the second one’s five.
- it gets cheaper after that.
- so any customers in the audience, it’s okay.
- all right, but, this is this one’s quite expensive.
- this is to bring up board.
- and um, and the way it's going to go to production is like this one here, okay, and so you’re going to take this it has two Blackwell chips and four Blackwell dies, connected to a Grace CPU.

- the grace CPU has a super fast chip-to-chip link, what’s amazing is, this computer is the first of its kind where this much computation.
- first of, all fits into this small of a place.
- second, it’s memory coherent.
- they feel like they’re just one big happy family, working on one application together, and so everything is coherent within it.
- um the just the amount of, you know, you saw the numbers there’s a lot of terabytes this and terabytes that.
- um but this is, this is a miracle.
- this is a, this, let’s see what are some of the things on here.
- uh there’s um uh NVLink 18 on top, PCI Express 19 on the bottom, on on uh your which one is mine and your left.
- one of them, it doesn’t matter, uh one of them, one of them is a CPU chip-to-chip link, is my left, or your depending on which side.
- I was just, I was trying to sort that out, and I just kind of, doesn’t matter.
- hopefully it comes plugged in.
- so okay, so this is the Grace Blackwell system.
2nd Gen Transformer Engine
- but there’s more, so it turns out, it turns out, all of the specs is fantastic, but we need a whole lot of new features.
- uh in order to push the limits beyond, if you will, the limits of physics we would like to always get a lot more X factors, and so one of the things that we did, was we invented another Transformer engine, another Transformer engine, the second generation.
- it has the ability to dynamically and automatically rescale and recas numerical formats to a lower precision whenever it can.
- remember artificial intelligence is about probability, and so you kind of have, you know, 1.7 approximately, 1.7 time approximately 1.4, to be approximately something else.
- does that make sense.
- and so, so the the ability for the mathematics to retain the precision and the range necessary in that particular stage of the pipeline super important.
- and so this is, it’s not just about the fact that we designed a smaller ALU.
- the world’s not quite that simple.
- you’ve got to figure out, when you can use.
- that across a computation that is thousands of GPUs, it’s running for weeks and weeks on weeks.
5th Gen NVLink
- and you want to make sure that the training job is going to converge.
- and so this new Transformer engine we have a fifth generation NVIDIA NVLink.
- it’s now twice as fast as Hopper, but very importantly it has computation in the network.
- and the reason for that is because when you have so many different GPUs working together, we have to share our information with each other.
- we have to synchronize and update each other and every so often we have to reduce the partial products, and then rebroadcast out the partial products, the sum of the partial products, back to everybody else, and so there’s a lot of what is called all reduce and all to all and all gather.
- it’s all part of this area of synchronization and collectives, so that we can have GPUs working with each other having extraordinarily fast links, and being able to do mathematics right in the network allows us to essentially amplify even further.
RAS Engine (Self-Test)
- so even though it’s 1.8 terabytes per second, it’s effectively higher than that, and so it’s many times that of Hopper the like a supercomputer running for weeks on (in) is approximately zero.
- and the reason for that is because there’s so many components working at the same time, the statistic the probability of them working continuously is very low, and so we need to make sure that whenever there is a well we checkpoint, and restart as often as we can.
- but if we have the ability to detect a weak chip or a weak node early, we could retire it, and maybe swap in another processor.
- that ability to keep the utilization of the supercomputer high.
- especially when you just spent $2 billion building it, is super important.
- and so we put in a RAS Engine, a reliability engine that does 100% self test, in system test, of every single gate, every single bit of memory on the Blackwell chip, and all the memory that’s connected to it.
- it’s almost as if we shipped with every single chip its own advanced tester that we test our chips with.
- this is the first time we’re doing this super excited about it.
Secure AI
- secure AI, only this conference do they clap for RAS, the the uh secure AI uh obviously you’ve just spent hundreds of millions of dollars creating a very important AI.
- and the the code, the intelligence of that AI is encoded in the parameters, you want to make sure that on the one hand you don’t lose it, on the other hand it doesn’t get contaminated.
- and so we now have the ability to encrypt data, of course, at rest, but also in transit, and while it’s being computed, it’s all encrypted.
- and so we now have the ability to encrypt and transmission, and when we’re computing it, it is in a trusted trusted environment, trusted engine environment.
Decompression Engine
- and the last thing is decompression.
- moving data in and out of these nodes when the compute is so fast becomes really essential.
- and so we’ve put in a high line speed compression engine, and effectively moves data 20 times faster in and out of these computers.
Blackwell vs Hopper
- these computers are so powerful, and there’s such a large investment, the last thing we want to do is have them be idle, and so all of these capabilities are intended to keep Blackwell fed, and as busy as possible.
- overall compared to Hopper, it is two and a half times, the fp8 performance for training per chip.

- it is ALS it also has this new format called fp6, so that even though the computation speed is the same, the bandwidth that’s amplified.
- because of the memory the amount of parameters, you can store in the memory is now amplified.
- fp4 effectively doubles the throughput.
Inference | Content Token Generation ⭐️⭐️⭐️
- this is vitally important for inference one of the things.
- that is becoming very clear, is that whenever you use a computer with AI on the other side, when you're chatting with the chatbot when you're asking it to review or make an image, remember in the back is a GPU generating tokens, some people call it inference, but it's more appropriately generation.
- the way that computing is done in the past was retrieval, you would grab your phone, you would touch something, um some signals go off, basically an email goes off to some storage somewhere.
- there’s pre-recorded content, somebody wrote a story, or somebody made an image, or somebody recorded a video, that record pre-recorded content is then streamed back to the phone, and recomposed in a way, based on a recommender system to present the information to you.
- you know that in the future the vast majority of that content will not be retrieved, and the reason for that is because that was pre-recorded by somebody who doesn't understand the context, which is the reason why we have to retrieve so much content.
- if you can be working with an AI that understands the context, who you are, for what reason you're fetching this information, and produces the information for you, just the way you like it.
- the amount of energy we save, the amount of networking bandwidth we save, the amount of waste of time we save, will be tremendous.
- the future is generative, which is the reason why we call it generative AI, which is the reason why this is a brand new industry.
- the way we compute is fundamentally different.
- we created a processor for the generative AI era.
- and one of the most important parts of it is content token generation.
- we call it this format is fp4.
- well that’s a lot of computation.
- 5x the Gen token generation, 5x the inference capability of Hopper, seems like enough, but why stop there.
- the answer is it’s not enough, and I’m going to show you why.
- I’m going to show you why.
Bigger GPU, 1000x AI Compute
- and so we would like to have a bigger GPU, even bigger than this one.
- and so we decided to scale it.
- and notice but first let me just tell you how we’ve scaled.
- over the the last eight years we’ve increased computation by 1,000 times.
- 8 years.
- 1,000 times.

- remember back in the good old days of Moore's Law.
- it was 2x 5x 10x every 5 years.
- that’s easiest math 10x every 5 years, a 100 times every 10 years.
- 100 times every 10 years in the middle, in the hey days of the PC Revolution, 100 times every 10 years in the last 8 years, we’ve gone 1,000 times, we have two more years to go.
- and so that puts it in perspective the rate at which we’re advancing computing is insane.
- and it’s still not fast enough.
NVLink Switch Chip
- so we built another chip.
- this chip is just an incredible chip, we call it the NVLink Switch 20.

- it’s 50 billion transistors.
- it’s almost the size of Hopper, all by itself.
- this switch ship has four NVLinks in it.
- each 1.8 terabytes per second, and it has computation in as I mentioned.
- what is this chip for, if we were to build such a chip, we can have every single GPU, talk to every other GPU, at full speed, at the same time.
- that’s insane.
- it doesn’t even make sense, but if you could do that, if you can find a way to do that, and build a system to do that, that’s cost effective, that’s cost effective.
- how incredible would it be, that we could have all these GPUs connect over a coherent link, so that they effectively are one giant GPU.
- well one of one of the great inventions, in order to make a cost effective, is that, this chip has to drive copper directly.
- the series of this chip, is just a phenomenal invention, so that we could do direct drive to copper, and as a result you can build a system that looks like this.
DGX GB200 NVL72
- now this system this system is kind of insane.
- this is one DGX.
- this is what a DGX looks like now. (DGX GB200 NVL72)

- remember just six years ago, it was pretty heavy but I was able to lift, it I delivered the uh the uh first DGX-1 to OpenAI, and the researchers there, you know the pictures are on the internet and we all autographed it.
- uh and um uh, if you come to my office it’s autographed there, is really beautiful.
- and but but you could lift it.
- uh this DGX, this DGX, that DGX by the was 170 teraflops, if you’re not familiar with the numbering system that’s 0.17 petaflops (PFLOPS).
- so this is 720, the first one I delivered to OpenAI was 0.17.
- you could round it up to 0.2, won’t make any difference.
- but and back then, was like wow, you know 30 more petaflops, and so this is now 720 petaflops, almost an exaflops, for training and the world's first one exaflops machine in one rack.
- just so you know, there are only a couple two three exaflops machines on the planet as we speak.
- and so this is an exaflops AI system in one single rack.
The Back, The DGX NVLink Spine
- well let’s take a look at the back of it.
- so this is what makes it possible.
- that’s the back, that's the back, the DGX NVLink spine 130 terabytes per second goes through the back of that chassis.

- that is more than the aggregate bandwidth of the internet.
- so we we could basically send everything to everybody within a second.
- and so we have 5,000 cables, 5,000 NVLink cables in total 2 miles.
- now this is the amazing thing, if we had to use optics, we would have had to use transceivers and retimer.
- and those transceivers and retimer alone would have cost 20,000 watts.
- 2 kilowatts of just transceivers alone.
- just to drive the NVLink spine.
- as a result we did it completely for free over NVLink switch.
- and we were able to save the 20 kilowatts for computation.
- this entire rack is 120 kilowatts so that 20 kilowatts makes a huge difference.
- it’s liquid cooled what goes in is 25° C, about room temperature.
- what comes out is 45°c, about your jacuzzi.
- so room temperature goes in, jacuzzi comes out, 2 liters per second. we could sell a peripheral, 600,000 parts.
What a GPU looks like to Jensen
- somebody used to say, you know, you guys make GPUs, and we do, but this is what a GPU looks like to me.

- when somebody says GPU, I see this, two years ago when I saw a GPU was the HGX 21 , it was 70 lb, 35,000 Parts.
- our GPUs now, are 600,000 parts, and 3,000 lb.
- 3,000 lb.
- 3,000 lb that’s kind of like the weight of a you know Carbon Fiber Ferrari.
- I don’t know if that’s useful metric, but everybody’s going I feel it, I feel it, I get it, I get that.
- now that you mention that I feel it.
- I don’t know what’s 3,000 lb.
- okay so 3,000 lb, ton and a half.
- so it’s not quite an elephant.
- so this is what a DGX 22 looks like.
- now let’s see what it looks like in operation.
- okay let’s imagine, what is what how do we put this to work, and what does that mean.
Training Operation
- well if you were to train a GPT model, 1.8 trillion parameter model, it took it took about apparently about, you know, 3 to 5 months or so, uh with 25,000 amp.

- uh if we were to do it with Hopper, it would probably take something like 8,000 GPUs, and it would consume 15 megawatts, 8,000 GPUs on 15 megawatts, it would take 90 days, about 3 months.
- and that would allows you to train something, that is, you know, this groundbreaking AI model, and this is obviously, not as expensive as as um as anybody would think.
- but it’s 8,000 GPUs.
- it’s still a lot of money, and so 8,000 GPUs, 15 megawatts.
- if you were to use Blackwell to do this, it would only take 2,000 GPUs.
- 2,000 GPUs, same 90 days, but this is the amazing part, only 4 megawatts of power so from 15 yeah that’s right.

- and that’s, and that’s our goal.
- our goal is to continuously drive down the cost and the energy, they're directly proportional to each other cost and energy, associated with the computing, so that we can continue to expand and scale up the computation that we have to do to train the next generation models.
- well this is training.
Inference | Generation Operation
- inference or generation is vitally important going forward.
- you know probably some half of the time that NVIDIA GPUs are in the cloud these days, it’s being used for token generation, you know, they’re either doing co-pilot this, or chat, you know, ChatGPT that, or um all these different models that are being used, when you’re interacting with it.
- or generating images, or generating videos, generating proteins, generating chemicals, there's a bunch of generation going on.
- all of that is in the category of computing, we call inference.
- but inference is extremely hard, for large language models.
- because these large language models have several properties.
- one they're very large, and so it doesn't fit on one GPU, this is, imagine Excel doesn’t fit on one GPU, you know, and imagine some application you’re running on a daily basis doesn’t run doesn’t fit on one computer.
- like a video game doesn’t fit on one computer.
- and most in fact, and many times in the past in hyperscale computing, many applications for many people fit on the same computer, and now all of a sudden, this one inference application where you’re interacting with, this chatbot, that chatbot requires a supercomputer in the back to run it.
- and that’s the future, the future is generative with these chatbots, and these chatbots are trillions of tokens, trillions of parameters, and they have to generate tokens at interactive rates.
- now what does that mean, well uh three tokens is about a word, I you know, the the uh you know, “Space: The final frontier. These are the voyages” that’s like that’s like 80 tokens.
- okay I don’t know, if that’s useful to you, and so you know the art of communications.
- is selecting an good analogies.
- yeah this is this is not going well.
- every I don’t know what he’s talking about.
- never seen Star Trek.
- and so and so so here we are we’re trying to generate these tokens.
- when you’re interacting with it you’re hoping that the tokens come back to you as quickly as possible.
- and as quickly as you can read it.
- and so the ability for generation tokens is really important.
- you have to parallelize the work of this model, across many many GPUs.
- so that you could achieve several things.
- one on the one hand you would like throughput, because that throughput reduces the cost, the overall cost per token of uh generating, so your throughput dictates the cost of of uh delivering the service.
- on the other hand you have another interactive rate, which is another tokens per second, where it's about per user, and that has everything to do with quality of service.
- and so these two things um uh compete against each other, and we have to find a way to distribute work across all of these different GPUs, and parallelize it in a way.
- that allows us to achieve both, and it turns out the search search space is enormous.
- you know I told you, there’s going to be math involved, and everybody’s going oh dear, I heard some gasp just now, when I put up that slide.

- you know, so this right here, the y-axis is tokens per second data center throughput, the x-axis is tokens per second interactivity of the person.
- and notice the upper right is the best.
- you want interactivity to be very high, number of tokens per second per user, you want the tokens per second of per data center to be very high, the upper right is terrific.
- however it’s very hard to do that.
- and in order for us to search for the best answer, across every single one of those intersections, XY coordinates.
- okay so you just look at every single XY coordinate, all those blue dots came from some repartitioning of the software.
- some optimizing solution has to go and figure out, whether to use tensor parallel, expert parallel, pipeline parallel, or data parallel, and distribute this enormous model across all these different GPUs, and sustain performance that you need.
- this exploration space would be impossible, if not for the programmability of NVIDIA’s GPUs.
- and so we could because of CUDA, because we have such rich ecosystem, we could explore this universe, and find that green roof line.
- it turns out that green roof line, notice you got TP2 EP8 DP4, it means two tensor parallel, across two GPUs, expert parallels across eight, data parallel across four.
- notice on the other end, you got tensor parallel cross 4, and expert parallel across 16.
- the configuration the distribution of that software it’s a different runtime, that would produce these different results.
- and you have to go discover that roof line.
- well that's just one model, and this is just one configuration of a computer.
- imagine all of the models being created around the world, and all the different configurations of systems that are going to be available.
- so now that you understand the basics.
Inference of Blackwell compared to Hopper
- let’s take a look at inference of Blackwell compared to Hopper.
- and this is the extraordinary thing.
- in one generation because we created a system that’s designed for trillion parameter generative AI.
- the inference capability of Blackwell is off the charts.
- and in fact it is some 30 times Hopper.

- for large language models like ChatGPT and others like it, the blue line is Hopper, I gave you, imagine, we didn’t change the architecture of Hopper, we just made it a bigger chip.
- we just used the latest, you know, greatest, uh 10 terabytes per second we connected the two chips together.
- we got this giant 208 billion parameter chip, how would we have performed if nothing else changed.
- and it turns out quite wonderfully.
- quite wonderfully.
- and that’s the purple line.
- but not as great as it could be.
- and and that’s where the fp4 tensor core, the new Transformer engine, and very importantly the NVLink Switch.
- and the reason for that is because all these GPUs have to share the results.
- partial price.
- whenever they do all to all all all gather whenever they communicate with each other, that NVLink Switch is communicating almost 10 times faster, than what we could do in the past using the fastest networks.
- Okay so Blackwell is going to be just an amazing system for a generative AI.
Generation of Intelligence
- and in the future, data centers are going to be thought of as, I mentioned earlier, as an AI Factory.
- an AI Factory's goal in life is to generate revenues, generate in this case, intelligence in this facility, not generating electricity as in AC generator of the last industrial revolution and this industrial revolution the generation of intelligence.
- and so this ability is super super important.
- the excitement of Blackwell is really off the charts.
- you know.
Customers of Blackwell
- when we first, you know, this is a year and a half ago, two years ago, I guess two years ago, when we first started to to go to market with Hopper, you know we had the benefit of two CSPs (Cloud Service Providers) joined us in a launch, and we were you know delighted, um and so we had two customers, uh we have more now.
- (switch the slide to lots of customer logos on the display, but the slide display a little bit lag) unbelievable excitement for Blackwell.

- unbelievable excitement.
- and there’s a whole bunch of different configurations, of course, I showed you, the configurations that slide into the Hopper form factor, so that’s easy to upgrade.
- I showed you examples that are liquid cooled, that are the extreme versions of it.
- one entire rack that’s that’s uh connected by NVLink 72.
- uh we’re going to Blackwell is going to be ramping to the world’s AI companies of which there are so many now.
- doing amazing work in different modalities.
- the CSPs, every CSP is geared up, all the OEM and ODMs.
- Regional clouds, Sovereign AIs, and Telcos all over the world are signing up to launch with Blackwell.
- this Blackwell would be the the the most successful product launch in our history.
- and so I can’t wait to see that.
- um I want to thank I want to thank some partners that that are joining us in this.
Partner - AWS
- uh AWS is gearing up for Blackwell, they’re uh they’re going to build the first uh GPU with secure AI.

- they’re uh building out a 222 exaflops system.
- you know just now when we animated uh just now the digital twin, if you saw the the all of those clusters are coming down, by the way that is not just art, that is a digital twin of what we're building.
- that’s how big it’s going to be.
- besides infrastructure we’re doing a lot of things together with AWS.
- we’re CUDA accelerating SageMaker AI.
- we’re CUDA accelerating Bedrock AI.
- uh Amazon Robotics is working with us uh using NVIDIA Omniverse.
- and Isaac Sim AWS Health has NVIDIA Health integrated into it.
- so AWS has really leaned into Accelerated Computing.
Partner - Google
- uh Google is gearing up for Blackwell.

- GCP already has A100s, H100s, T4s, L4s a whole fleet of NVIDIA CUDA GPUs.
- and they recently announced the Gemma model that runs across all of it.
- uh we’re working to optimize uh and accelerate every aspect of GCP we’re accelerating data proc which for data processing their data processing engine, JAX, XLA, Vertex AI and MuJoCo for robotics so we’re working with uh Google and GCP across a whole bunch of initiatives.
Partner - Oracle
- uh Oracle is gearing up for Blackwell.

- Oracle is a great partner of ours, for NVIDIA DGX Cloud.
- and we’re also working together to accelerate something that’s really important to a lot of companies, Oracle database.
Partner - Microsoft
- Microsoft is accelerating, and Microsoft is gearing up for Blackwell.

- Microsoft NVIDIA has a wide-ranging partnership.
- we’re accelerating CUDA accelerating all kinds of services, when you chat obviously and uh AI services that are in Microsoft Azure, uh it’s very very likely NVIDIA is in the back.
- uh doing the inference and the token generation.
- uh they built the largest NVIDIA InfiniBand supercomputer, basically a digital twin of ours or a physical twin of ours.
- uh we’re bringing the NVIDIA ecosystem to Azure, NVIDIA DGX Cloud to Azure, uh NVIDIA Omniverse is now hosted in Azure, NVIDIA Healthcare is on Azure, and all of it is deeply integrated and deeply connected with Microsoft Fabric.
- the whole industry is gearing up for Blackwell.
- this is what I’m about to show you.
Partner - Wistron
- most of the most of the the the uh uh uh scenes that you’ve seen so far of Blackwell, are the are the full fidelity design of Blackwell.
- everything in our company has a digital twin.
- and in fact this digital twin idea is it is really spreading.
- and it it helps it helps companies build very complicated things, perfectly the first time.
- and what could be more exciting than creating a digital twin, to build a computer that was built in a digital twin.
- and so let me show you what Wistron is doing
- to meet the demand for NVIDIA Accelerated Computing.
- Wistron, one of our leading manufacturing partners is building digital twins of NVIDIA DGX and HGX factories using custom software developed with Omniverse SDKs and APIs.

- for their newest factory.
- Wistron started with a digital twin to virtually integrate their multi-CAD and process simulation data into a unified view.
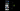
- testing and optimizing layouts in this physically accurate digital environment, increased worker efficency by 51%.

- during construction, the Omniverse digital twin was used to verify that the physical build matched the digital plans.

- identifying any discrepancies early has helped avoid costly change orders.

- and the results have been impressive, using a digital twin helped bring Wistron’s factory online in half the time.
- just 2 and 1/2 months instead of five.
- in operation the Omniverse digital twin helps Wistron rapidly test new layouts to accommodate new processes or improve operations in the existing space.

- and monitor real-time operations using live IoT data from every machine on the production line.


- which ultimately enabled Wistron to reduce end-to-end cycle times by 50% and defect rates by 40%.
- with NVIDIA AI and Omniverse, NVIDIA’s global ecosystem of partners are building a new era of accelerated AI enabled digitalization.

- that’s how we are, that’s the way it’s going to be in the future, we’re going to manufacturing everything digitally first, and then we'll manufacture it physically.
3️⃣ NIMs
AlexNet - First Contact (2012)
- people ask me how did it start, what got you guys so excited, what was it that you saw, that caused you to put it all in, on this incredible idea.
- and it’s this.
- hang on a second.
- guys that was going to be such a moment.
- that’s what happens when you don’t rehearse.
- this as you know, was First Contact, 2012, AlexNet, you put a cat into this computer, and it comes out and it says cat.

- and we said, oh my god, this is going to change everything.
- you take 1 million numbers, you take one million numbers, across three channels RGB, these numbers make no sense to anybody.
- you put it into this software, and it compress it dimensionally reduce it, it reduces it from a million dimensions, a million dimensions.
- it turns it into three letters.
- one vector.
- one number.
- and it’s generalized, you could have the cat, be different cats.
- and and you could have it be the front of the cat, and the back of the cat.
- and you look at this thing, you say unbelievable, you mean any cats.
- yeah any cat.
- and it was able to recognize all these cats.
- and we realized how it did it.
- systematically, structurally, it's scalable.
- how big can you make it.
- well how big do you want to make it.
- and so we imagine, that this is a completely new way of writing software.
- and now today as you know, you could have you type in, the word c a t, and what comes out is a cat, it went the other way.
- am I right, unbelievable.
- how is it possible.
- that’s right.
- how is it possible, you took three letters, and you generated a million pixels from it.
- and it made sense.
- well that’s the miracle.
- and here we are.
- just literally 10 years later.
- 10 years later.
- where we recognize text, we recognize images, we recognize videos, and sounds, and images not only do we recognize them, we understand their meaning, we understand the meaning of the text, that’s the reason why it can chat with you.

- it can summarize for you.
- it understands the text, it understood not just recognizes the the English, it understood the English.
- it doesn’t just recognize the pixels, and understood the pixels, and you can you can even condition it between two modalities.
- you can have language condition image, and generate all kinds of interesting things.
- well if you can understand these things, what else can you understand that you’ve digitized.
- the reason why we started with text, and you know images, is because we digitized those.
- but what else have we digitized.
- well it turns out we digitized a lot of things, proteins, and genes, and brain waves, anything you can digitize, so long as there's structure we can probably learn some patterns from it, and if we can learn the patterns from it, we can understand its meaning, if we can understand its meaning we might be able to generate it as well.
- and so therefore the Generative AI Revolution is here.
Earth-2 - CorrDiff
- well what else can we generate, what else can we learn, well one of the things, that we would love to learn, we would love to learn, is we would love to learn, climate, we would love to learn, extreme weather, we would love to learn, uh what how we can predict future weather at regional scales, at sufficiently high resolution, such that we can keep people out of harm’s Way, before harm comes.
- extreme weather cost the world $150 billion, surely more than that.
- and it’s not evenly distributed.
- $150 billion is concentrated in some parts of the world, and of course to some people of the world, we need to adapt, and we need to know what’s coming.
- and so we are creating Earth-2, a digital twin of the Earth for predicting weather, we and we’ve made an extraordinary invention, called CorrDiff.

- the ability to use generative AI to predict weather, at extremely high resolution.
- let’s take a look.
- as the earth’s climate changes, AI powered weather forecasting is allowing us to more accurately predict and track severe storms, like super typhoon chanthu which caused widespread damage in Taiwan and the surrounding region in 2021.

- current AI forecast models, can accurately predict the track of storms, but they are limited to 25 km resolution, which can miss important details.

- NVIDIA CorrDiff is a revolutionary new generative AI model, trained on high resolution radar assimilated Warf weather forecasts and air 5 reanalysis data.
- using CorrDiff, extreme events like chanthu can be super resolved from 25 km to 2 km resolution, with 1,000 times the speed, and 3,000 times the energy efficiency of conventional weather models.

- by combining the speed and accuracy of NVIDIA’s weather forecasting model FourCastNet, and generative AI models like CorrDiff we can explore hundreds or even thousands of kilometer scale regional weather forecasts, to provide a clear picture of the best, worst, and most likely impacts of a storm.

- this wealth of information can help minimize loss of life and property damage.
- today CorrDiff is optimized for Taiwan, but soon generative super sampling will be available as part of the in via Earth-2 inference service, for many regions across the globe.

The Weather Company
- The Weather Company has the trust a source of global weather predictions.

- we are working together to accelerate their weather simulation.
- first principled base of simulation, however they’re also going to integrate Earth-2 CorrDiff.
- so that they could help businesses and countries do regional high resolution weather prediction.
- and so if you have some weather prediction you’d like to know, like to do, uh reach out to the weather company .really exciting, really exciting work.
NVIDIA Healthcare
- NVIDIA Healthcare, something we started 15 years ago we’re super super excited about this, this is an area where we’re very very proud, whether it’s Medical Imaging or genene sequencing or computational chemistry.

- it is very likely that NVIDIA is the computation behind it.
- we’ve done so much work in this area.
- today we’re announcing, that we’re going to do something really really cool.
- imagine all of these AI models that are being used, to generate images and audio, but instead of images and audio, because it understood images and audio, all the digitization that we’ve done for, genes and proteins and amino acids, that digitalization capability, is now now passed through machine learning.
- so that we understand the language of life.
- the ability to understand the language of life, of course we saw the first evidence of it, with AlphaFold, this is really quite an extraordinary thing after decades of painstaking work, the world had only digitized, and reconstructed, using cor electron microscopy or Crystal XR X-ray crystallography, um these different techniques painstaking reconstructed the protein.
- 200,000 of them in just what is it less than a year, or so, AlphaFold has reconstructed 200 million proteins, basically every protein every of every living thing, that's ever been sequenced.
- this is completely revolutionary, well those models are incredibly hard to use, um for incredibly hard for people to build, and so what we’re going to do is we’re going to build them we’re going to build them for uh the the researchers around the world, and it won’t be the only one.
- there’ll be many other models that we create, and so let me show you what we’re going to do with it.
NVIDIA BioNeMo NIM
- virtual screening for new medicines is a computationally intractable problem.
- existing techniques can only scan billions of compounds, and require days on thousands of standard compute nodes, to identify new drug candidates.

- NVIDIA BioNeMo NIM enable a new generative screening paradigm, using NIMs for protein structure prediction with AlphaFold, molecule generation with MoIMIM and docking with DiffDock, we can now generate and screen candidate molecules in a matter of minutes.
- MoIMIM can connect to custom applications to steer the generative process, iteratively optimizing for desired properties.
- these applications can be defined with BioNeMo microservices or built from scratch.

- here a physics based simulation optimizes for a molecule’s ability to bind to a target protein, while optimizing for other favorable molecular properties in parallel.

- MoIMIM generates high quality drug-like molecules that bind to the target, and are synthesizable translating to a higher probability of developing successful medicines faster.


- BioNeMo is enabling a new paradigm in drug discovery with NIMs.
- providing on-demand microservices that can be combined to build powerful drug discovery workflows, like de novo protein design, or guided molecule generation for virtual screening.

- BioNeMo are helping researchers and developers, reinvent computational drug design.
NIM - NVIDIA Inference Microservice
- NVIDIA MoIMIM, CorrDiff there’s a whole bunch of other models whole bunch of other models, computer vision models, robotics models, and even of course some really really terrific open source language models.

- these models are groundbreaking.
- however it's hard for companies to use.
- how would you use it.
- how would you bring it into your company and integrate it into your workflow.
- how would you package it up and run it.
- remember earlier I just said, that inference is an extraordinary computation problem.
- how would you do the optimization, for each and every one of these models, and put together the computing stack necessary to run that supercomputer, so that you can run the models, in your company.
- and so we have a great idea.
- we’re going to invent a new way invent a new way for you, to receive and operate software.
- this software comes basically in a digital box we call it a container, and we call it the NVIDIA Inference Microservice.
- a NIM.

- and let me explain to you what it is.
- a NIM it’s a pre-trained model, so it’s pretty clever, and it is packaged and optimized to run across NVIDIA’s install base.
- which is very very large.
- what’s inside it is incredible.

- you have all these pre-trained state-of-the-art open source models.
- they could be open source, they could be from one of our partners, it could be created by us, like NVIDIA Omni.
- it is packaged up with all of its dependencies, so CUDA the right version, cuDNN the right version, TensorRT LLM distributing across the multiple GPUs, Triton Inference Server all completely packaged together.
- it’s optimized, depending on whether you have a single GPU, multi-GPU, or multi node of GPUs.
- it’s optimized for that, and it’s connected up with APIs that are simple to use.
- now this think about what an AI API is, an AI API is an interface that you just talk, to and so this is a piece of software in the future, that has a really simple API.
- and that API called human.
- and these packages incredible bodies of software, will be optimized and packaged and we’ll put it on a website, and you can download it.
- you could take it with you, you could run it, in any cloud you can run it in your own data center you can run in workstations if it fit.
- and all you have to do is come to ai.NVIDIA.com we call it NVIDIA inference microservice, but inside the company we all call it NIMs.

- okay just imagine, you know, one of some someday there there’s going to be one of these chatbots, and these chat bots is going to just be in a NIM.
- and you you’ll uh you’ll assemble a whole bunch of chatbots, and that’s the way software is going to be be built someday.
- how do we build software in the future.
- it is unlikely that you’ll write it from scratch, or write a whole bunch of python code, or anything like that.
- it is very likely that you assemble a team of AIs.

- there’s probably going to be a super AI that you use, that takes the mission that you give it, and breaks it down into an execution plan.
- some of that execution plan could be handed off to another NIM, that NIM would maybe uh understand SAP, the language of SAP is ABAP it might understand ServiceNow.
- and it go retrieve some information from their platforms.
- it might then hand that result to another NIM, who that goes off and does some calculation on it, maybe it’s an optimization software, a combinatorial optimization algorithm, maybe it’s uh you know some just some basic calculator.
- maybe it’s pandas, to do some numerical analysis on it.
- and then it comes back with its answer, and it gets combined with everybody else’s, and it because it’s been presented with this is what the right answer should look like it knows what answer what an what right answers to produce and it presents it to you.
- we can get a report every single day, at you know top of the hour, uh that has something to do with a bill plan or some forecast or uh some customer alert or some bugs database or whatever it happens to be.
- and we could assemble it using all these NIMs.
- and because these NIMs have been packaged up and ready to work on your systems, so long as you have video GPUs in your data center in the cloud, this this NIMs will work together as a team, and do amazing things.
- and so we decided, this is such a great idea we’re going to go do that.
- and so NVIDIA has NIMs running all over the company, we have chatbots being created all over the place, and one of the mo most important chatbots, of course is a chip designer chatbot.
- you might not be surprised we care a lot about building chips.
- and so we want to build chatbots, AI co-pilots, that are co-designers with our engineers.
NIM Demo
- and so this is the way we did it.
- so we got ourselves a Llama, Llama 2 this is a 70B, and it’s you know packaged up in a NIM.
- and we asked it you know uh what is a CTL.

- Well turns out CTL is an internal uh program and it has a internal proprietary language, but it thought the CTL was a combinatorial timing logic, and so it describes you know conventional knowledge of CTL, but that’s not very useful to us.
- and so we gave it a whole bunch of new examples.
- you know this is no different than employee, onboarding an employee, uh we say you know thanks for that answer, it’s completely wrong, um and and uh and then we present to them, uh this is what a CTL is.
- okay and so this is what a CTL is at NVIDIA.

- and the CTL, as you can see you know CTL stands for Compute Trace Library which makes sense.
- you know we were tracing compute cycles all the time and it wrote the program.
- isn’t that amazing.
- and so the productivity of our chip designers can go up, this is what you can do with a NIM.
- first thing you can do with is customize it.
- we have a service called NeMo Microservices.

- that helps you curate the data, preparing the data, so that you could teach this, on board this AI, you fine-tune them, and then you guardrail it you can even evaluate the answer, evaluate its performance against um other other examples.
- and so that’s called the NeMo Microservices.
4️⃣ NeMo and AI Foundry
AI Foundry & Three Pillars ⭐️⭐️⭐️
- now the thing that’s that’s emerging here is this there are three elements three pillars of what we’re doing.
- the first pillar is, of course inventing the technology for um uh AI models and running AI models, and packaging it up for you.
- the second is to create tools to help you modify it, first is having the AI technology, second is to help you modify it, and third is infrastructure for you to fine-tune it, and if you like deploy it, you could deploy it on our infrastructure called DGX cloud.
- or you can employ deploy it on-prem.
- you can deploy it anywhere you like.
- once you develop it it’s yours to take anywhere.
- and so we are effectively an AI Foundry.
- we will do for you and the industry on AI, what tsmc does for us building chips.
- and so we go to it with our go to tsmc with our big ideas, they manufacture and we take it with us.
- and so exactly the same thing here AI Foundry, and the three pillars, are the NIM, NeMo Microservices, and DGX Cloud.
Data Process | Knowledge Process | NeMo Retriever
- the other thing that you could teach the NIM to do it, to understand your proprietary information.
- remember inside our company, the vast majority of our data is not in the cloud, it's inside our company.
- it’s been sitting there.
- you know being used all the time, and and gosh it’s it’s basically invidious intelligence.
- we would like to take that data, learn its meaning, like we learned the meaning of almost anything else that we just talked about, learn its meaning.
- and then reindex that knowledge into a new type of database, called a vector database, and so you essentially take structured data or unstructured data, you learn its meaning, you encode its meaning, so now this becomes an AI database, and that AI database in the future, once you create it, you can talk to it.
- and so let me give you an example of what you could do.

- so suppose you create you get you got a whole bunch of multi modality data, and one good example of that, is PDF.
- so you take the PDF, you take all of your PDFs, all the all your favorite you know the stuff that that is proprietary to you critical to your company, you can encode it, just as we encoded pixels of a cat, and it becomes the word cat.
- we can encode all of your PDF, and it turns into vectors, that are now stored inside your vector database.

- it becomes the proprietary information of your company.
- and once you have that proprietary information, you can chat to it.
- it’s an it’s a smart database.
- and so you just ch chat with data.
- and how how much more enjoyable is that.
- you know we for for our software team, you know they just chat with the bugs database.
- you know how many bugs was there last night, um are we making any progress, and then after you’re done talking to this uh bugs database you need therapy.
- and so so we have another chatbot for you.
- you can do it.
- okay so we call this NeMo Retriever, and the reason for that is because ultimately it’s job is to go retrieve information as quickly as possible.
- and you just talk to it.
- hey retrieve me this information it goes if brings it back to you.
- and do you mean this you go yeah perfect.
- okay and so we call it the NeMo Retriever.
- well the NeMo services helps you create all these things and we have all all these different NIMs.
NIM of Digital Human
- we even have NIMs of digital humans.
- I’m Rachel.
- your AI care manager.

- okay so so it’s a really short clip.
- but there were so many videos to show you I guess so many other demos to show you.
- and so I I had to cut this one short.
- but this is Diana she is a digital human NIM.
- and and uh you just talked to her, and she’s connected, in this case to Hippocratic AI’s large language model for healthcare.
- and it’s truly amazing.
- she is just super smart about Healthcare things.
- you know.
- and so after you’re done after my my Dwight my VP of software engineering, talks to the chatbot for bugs database, then you come over here and talk to Diane.
- and and so so uh Diane is is um completely animated with AI, and she’s a digital human.
Enterprise IT Gold Mine
- uh there’s so many companies that would like to build they’re sitting on gold mines.
- the the Enterprise IT industry is sitting on a gold mine.
- it’s a gold mine because they have so much understanding of of uh the way work is done.
- they have all these amazing tools that have been created over the years.
- and they’re sitting on a lot of data.
- if they could take that gold mine, and turn them into co-pilots.
- these co-pilots could help us do things.
- and so just about every it franchise, it platform in the world, that has valuable tools that people use, is sitting on a gold mine for co-pilots, and they would like to build their own co-pilots, and their own chatbots.
- and so we’re announcing that NVIDIA AI foundary is working with some of the world’s great companies.
- SAP generates 87% of the world’s global commerce, basically the world runs on SAP, we run on SAP.
- NVIDIA and SAP are building SAP Jewel co-pilots uh using NVIDIA NeMo and DGX cloud,

- ServiceNow they run 80 85% of the world’s Fortune 500 companies run their people and customer service operations on servicenow.
- and they’re using NVIDIA AI Foundry to build ServiceNow uh assist virtual assistance.

- Cohesity backs up the world’s data they’re sitting on a gold mine of data. hundreds of exobytes of data over 10,000 companies.
- NVIDIA AI Foundry is working with them, helping them, build their Gaia generative AI agent.

- snowflake is a company that stores the world’s uh digital warehouse in the cloud, and serves over 3 billion queries a day, for 10,000 enterprise customers.
- snowflake is working with NVIDIA AI Foundry to build co-pilots with NVIDIA NeMo and NIMs.

- NetApp nearly half of the files in the world, are stored on-prem, on NetApp.
- NVIDIA AI Foundry is helping them, uh build chatbots and co-pilots like those vector databases and retrievers with NVIDIA NeMo and NIMs.

- and we have a great partnership with Dell.
- everybody who everybody who is building these chatbots and generative AI, when you’re ready to run it, you’re going to need an AI Factory.
- and nobody is better at building end-to-end systems of very large scale, for the enterprise, than Dell.
- and so anybody any company every company will need to build AI factories, and it turns out that Michael is here, he's happy to take your order.

- ladies and gentlemen Michael Dell.

5️⃣ Omniverse and AI Robotics
AI Robotics
- okay let’s talk about the next wave of Robotics.
- the next wave of AI robotics.
- physical AI.
- so far all of the AI, that we've talked about, is one computer.

- data comes into one computer lots of the world’s if you will experience in digital text form.
- the AI imitates us.
- by reading a lot of the language, to predict the next words, it’s imitating You, by studying all of the patterns, and all the other previous examples.
- of course it has to understand context and so on so forth.
- but once it understands the context it’s essentially imitating you.
- we take all of the data we put it into a system like DGX, we compress it into a large language model, trillions and trillions of parameters become billions and billion, trillions of tokens becomes billions of parameters these billions of parameters becomes your AI.
- well in order for us to go to the next wave of AI, where the AI understands the physical world, we're going to need three computers.
- the first computer is still the same computer, it's that AI computer, that now is going to be watching video, and maybe it’s doing synthetic data generation, and maybe there’s a lot of human examples, just as we have human examples in text form, we’re going to have human examples in articulation form, and the AIs will watch us, understand what is happening, and try to adapt it for themselves, into the context.
- and because it can generalize with these foundation models, maybe these robots can also perform in the physical world, fairly generally, so I just described in very simple terms, essentially what just happened in large language models, except the ChatGPT moment for robotics may be right around the corner.
- and so we’ve been building the end to-end systems, for robotics for some time.
- I’m super super proud of the work, we have the AI system DGX, we have the lower system which is called AGX, for autonomous systems, the world’s first robotics processor when we first built this thing people are what are you guys building.
- it's SoC, it’s one chip it’s designed to be very low power.
- but it’s designed for high-speed sensor processing, and AI.
- and so if you want to run Transformers in a car, or you want to run Transformers in a in a you know anything, um that moves uh we have the perfect computer for you.
- it’s called the Jetson.
- and so the DGX on top for training the AI, the Jetson is the autonomous processor, and in the middle we need another computer.
- whereas large language models have the benefit, of you providing your examples and then doing reinforcement learning human feedback, what is the reinforcement learning human feedback of a robot.
- well it’s reinforcement learning physical feedback.
- that’s how you align the robot.
- that’s how you that’s how the robot knows, that as it’s learning these articulation capabilities and manipulation capabilities, it’s going to adapt properly, into the laws of physics.
- and so we need a simulation engine, that represents the world digitally, for the robot.
- so that the robot has a gym to go learn how to be a robot.
- we call that virtual world Omniverse.
- and the computer that runs Omniverse is called OVX.
- and OVX the computer itself is hosted in the Azure Cloud.
- okay and so basically we built these three things, these three systems.
- on top of it we have algorithms for every single one.
Robotics Building
- now I’m going to show you, one super example of how AI and Omniverse are going to work together.
- the example I’m going to show, you is kind of insane, but it’s going to be very very close to tomorrow.
- it’s a robotics building, this robotics building, is called a warehouse, inside the robotics building are going to be some autonomous systems.
- some of the autonomous systems are going to be called humans, and some of the autonomous systems are going to be called forklifts, and these autonomous systems are going to interact with each other of course autonomously.
- and it’s going to be overlooked upon by this warehouse to keep everybody out of harm’s way.
- the warehouse is essentially an air traffic controller, and whenever it sees something happening, it will redirect traffic, traffic and give new way points just new way points to the robots and the people and they’ll know exactly what to do.
- this warehouse this building you can also talk to, of course you could talk to it.
- hey you know SAP Center how are you feeling today.
- for example and so you could ask the same the warehouse the same questions.
- basically the system I just described, will have Omniverse Cloud, that’s hosting the virtual simulation, and AI running on DGX cloud, and all of this is running in real time.
The Future of Heavy Industry | Digital Twins
- let’s take a look.
- the future of heavy industry starts as a digital twin.

- the AI agents helping robots, workers and infrastructure navigate unpredictable events in complex industrial spaces will be built and evaluated first in sophisticated digital twins.



- this Omniverse digital twin of a 100,000 ft warehouse is operating as a simulation environment, that integrates digital workers, amrs running the NVIDIA Isaac Perceptor stack, centralized activity maps of the entire warehouse from 100 simulated ceiling mount cameras using NVIDIA Metropolis, and AMR route planning with NVIDIA cuOpt software in loop testing of AI agents in this physically accurate simulated environment, enables us to evaluate and refine how the system adapts to real world unpredictability.






- here an incident occurs along this AMR’s planned route, blocking its path as it moves to pick up a pallet.





- NVIDIA Metropolis updates and sends a realtime occupancy map to cuOpt, where a new optimal route is calculated.
- the AMR is enabled to see around corners, and improve its mission efficiency.
- with generative AI powered Metropolis Vision Foundation models, operators can even ask questions using natural language.

- the visual model understands nuanced activity, and can offer immediate insights to improve operations.
- all of the sensor data is created in simulation and passed to the real-time AI.

- running as NVIDIA Inference Microservices or NIMs.
- and when the AI is ready to be deployed in the physical twin, the real warehouse we connect Metropolis and Isaac NIMs to real sensors with the ability for continuous Improvement of both the digital twin and the AI models.


- isn’t that incredible.
- and so remember remember a future facility, warehouse, factory, building, will be software defined, and so the software is running how else would you test the software, so you you you test the software to building the warehouse, the optimization system in the digital twin, what about all the robots all of those robots you are seeing just now, they’re all running their own autonomous robotic stack, and so the way you integrate software in the future, CI/CD in the future, for robotic systems is with digital twins.
Omniverse Cloud APIs
- we’ve made Omniverse a lot easier to access.
- we’re going to create basically Omniverse Cloud APIs, four simple API and a channel, and you can connect your application to it.

- so this is this is going to be as wonderfully, beautifully, simple in the future that Omniverse is going to be.
- and with these APIs you’re going to have these magical digital twin capability.
- we also have turned Omniverse into an AI and integrated it with the ability to chat USD, the the language of our language is you know human and Omniverse is language as it turns out is universal scene description.

- and so that language is rather complex, and so we’ve taught our Omniverse uh that language.
- and so you can speak to it in English and it would directly generate USD.
- and it would talk back in USD, but converse back to you in English, you could also look for information in this world semantically.
- instead of the world being encoded semantically in in language now it's encoded semantically in scenes.
- and so you could ask it of of uh certain objects, or certain conditions and certain scenarios, and it can go and find that scenario for you.
- it also can collaborate with you in generation, you could design some things in 3D, it could simulate some things in 3D, or you could use AI to generate something in 3D.
- let’s take a look, at how this is all going to work.
- we have a great partnership with SIEMENS.

- SIEMENS is the world’s largest industrial engineering and operations platform.
- you’ve seen now so many different companies, in the industrial space, heavy Industries is one of the greatest final frontiers of it, and we finally now have the Necessary Technology to go and make a real impact.
- SIEMENS is building the industrial metaverse and today we’re announcing that SIEMENS is connecting their crown jewel Xcelerator to NVIDIA Omniverse.
- let’s take a look.
- SIEMENS technology is transformed every day, for everyone.
- Teamcenter X our leading product life cycle management software from the SIEMENS Xcelerator platform is used every day by our customers, to develop, and deliver products at scale.



- now we are bringing the real and the digital worlds even closer by integrating NVIDIA AI and Omniverse Technologies into Teamcenter X.
- Omniverse APIs enable data interoperability and physics-based rendering to Industrial scale design and manufacturing projects.

- our customers HD Hyundai, market leader in sustainable ship manufacturing builds ammonia and hydrogen power ships often comprising over 7 million discrete parts.

- with Omniverse APIs, Teamcenter X lets companies like HD Hyundai, unify and visualize these massive engineering data sets interactively.

- and integrate generative AI to generate 3D objects or HDRi backgrounds to see their projects in context.

- the result an ultra inuitive photoal physics-based digital twin that eliminates waste and errors.
- delivering huge savings in cost and time.
- and we are building this for collaboration.
- whether across more SIEMENS Xcelerator tools like SIEMENS NX or STAR-CCM+ or across teams working on their favorite devices, in the same scene together.

- in this is just the beginning, working with NVIDIA we will bring accelerated computing, generative AI and Omniverse integration across the SIEMENS Xcelerator portfolio.

- the pro the the professional, the professional voice actor, happens to be a good friend of mine, Roland Busch who happens to be the CEO of SIEMENS.
Nissan
- once you get Omniverse connected into your workflow, your ecosystem, from the beginning of your design, to engineering, to manufacturing planning, all the way to digital twin operations.

- once you connect everything together, it’s insane, how much productivity you can get, and it’s just really really wonderful.
- all of a sudden everybody is operating on the same ground truth.
- you don’t have to exchange data and convert data make mistakes everybody is working on the same ground truth.
- from the design department, to the art department, the architecture department all the way to the engineering and even the marketing department.
- let’s take a look at how Nissan has integrated Omniverse into their workflow, and it’s all because it’s connected by all these wonderful tools, and these developers that we’re working with.
- take a look.







Omniverse Cloud streams to The Vision Pro
- that was not an animation, that was Omniverse, today we're announcing that Omniverse Cloud streams to The Vision Pro.

- and it is very very strange, that you walk around virtual doors, when I was getting out of that car, and everybody does it, it is really really quite amazing.
- Vision Pro connected to Omniverse portals you into Omniverse.
- and because all of these CAD tools, and all these different design tools are now integrated and connected to Omniverse.
- you can have this type of workflow, really incredible.
Robotics
- let’s talk about robotics, everything that moves will be robotic there’s no question about that.
- it’s safer it’s more convenient, and one of the largest Iindustries is going to be automotive.

- we build the robotic stack, from top to bottom as I was mentioned.
- from the computer system, but in the case of self-driving cars, including the self-driving application.
- at the end of this year or I guess beginning of next year, we will be shipping in Mercedes, and then shortly after that JLR (Jaguar Land Rover).
- and so these autonomous robotic systems, are software defined, they take a lot of work to do, has computer vision has obviously artificial intelligence, control and planning, all kinds of very complicated technology, and takes years to refine.
- we’re building the entire stack.
- however we open up our entire stack, for all of the automotive industry, this is just the way we work.
- the way we work in every single industry we try to build as much of it as we can so that we understand it. but then we open it up so everybody can access it.
- whether you would like to buy just our computer, which is the world’s only full functional save ASIL-D system that can run AI this functional safe ASIL-D quality computer or the operating system on top or of course our data centers which is in basically every AV company in the world.
- however you would like to enjoy it we’re delighted buy it.
- today we’re announcing that BYD the world’s largest ev company is adopting our next generation it’s called Thor.
- Thor is designed for Transformer engines. Thor, our next generation AV computer will be used by BYD.
- you probably don’t know this fact, that we have over a million robotics developers.
- we created Jetson this robotics computer.
- we’re so proud of it.
- the amount of software that goes on top of it is insane.
- but the reason why we can do it at all, is because it’s 100% CUDA compatible.
- everything that we do, everything that we do in our company, is in service of our developers.
- and by us being able to maintain this rich ecosystem, and make it compatible with everything that you access from us, we can bring all of that incredible capability, to this little tiny computer, we call Jetson.
- a robotics computer.
- we also today are announcing, this incredibly advanced new SDK, we call it Isaac Perceptor.

- Isaac Perceptor, most most of the bots today are pre-programmed, they’re either following rails on the ground digital rails or theyd be following AprilTags, but in the future they’re going to have perception.
- and the reason why you want that, is so that you could easily program it you say would you like to go from point A to point B and it will figure out a way to navigate its way there.
- so by only programming waypoints, the entire route could be adaptive, the entire environment could be reprogrammed, just as I showed you at the very beginning with the warehouse.
- you can’t do that with pre-programmed AGVs.
- if those boxes fall down, they just all gum up and they just wait there.
- for somebody to come clear it and so now with the Isaac Perceptor we have incredible state-of-the-art vision odometry 3D reconstruction, and in addition to 3D reconstruction depth perception.
- the reason for that is so that you can have two modalities, to keep an eye on what’s happening in the world.
- Isaac Perceptor, the most used robot today, is the manipulator manufacturing arms and they are also pre-programmed.

- the computer vision algorithms, the AI algorithms, the control and path planning algorithms, that are geometry aware incredibly computational intensive.
- we have made these CUDA accelerated.
- so we have the world’s first CUDA accelerated motion planner, that is geometry aware, you put something in front of it, it comes up with a new plan, and our articulates around it, it has excellent perception for pose estimation of a 3D object.
- not just not it’s pose in 2D, but it’s pose in 3D.
- so it has to imagine what’s around, and how best to grab it.
- so the foundation pose, the grip foundation, and the um articulation algorithms, are now available, we call it Isaac Manipulator.
- and they also uh just run on NVIDIA’s computers.
- we are are starting to do some really great work, in the next generation of robotics.
Humanoid Robotics
- the next generation of Robotics, will likely be a humanoid robotics.
- we now have the necessary technology, and as I was describing earlier.
- the necessary technology to imagine, generalized human robotics.
- in a way human robotics is likely easier, and the reason for that is because we have a lot more imitation training data that we can provide there robots.
- because we are constructed in a very similar way.
- it is very likely that the human robotics will be much more useful, in our world, because we created the world to be something that we can interoperate in and work well in.
- and the way that we set up our workstations and nanufacturing and logistics they were designed for for humans, they were designed for people, and so these human robotics will likely be much more productive to deploy.
- while we’re creating just like we’re doing with the others, the entire stack, starting from the top, a foundation model that learns from watching video, human, human examples, it could be in video form, it could be in virtual reality form, we then created a gym for it called Isaac Reinforcement Learning Gym, which allows the humanoid robot to learn how to adapt to the physical world, and then an incredible computer, the same computer that’s going to go into a robotic car, this computer will run inside a human or robot called Thor.
- it’s designed for Transformer engines.
- we’ve combined several of these into one video.
- this is something that you’re going to really love.
- take a look.
Demo of Robotics
- it’s not enough for humans to imagine.
- we have to invent.
- and explore real.
- and push beyond what’s been done.
- fair amount of detail.
- we create smarter, and faster.

- we push it to fail.
- so it can learn.

- we teach it, then help it teach itself.

- we broaden its understanding, to take on new challenges, with absolute precision, and succeed.
Image not found.


- we make it perceive, and move, and even reason, so it can share our world with us.



- this is where inspiration leads us the next frontier.
- this is NVIDIA Project GR00T.
- a general purpose Foundation Model, for humanoid robot learning, the group model takes multimodal instructions, and past interactions as input, and produces the next action for the robot to execute.


- we developed Isaac lab, a robot learning application to train GR00T.
- Omniverse Isaac Sim and we scale out with osmo a new compute orchestration service that coordinates workflows across DGX systems for training, and OVX systems for simulation.


- with these tools, we can train GR00T in physically based simulation, and transfer zero shot to the real world.


- the GR00T model will enable a robot to learn from a handful of human demonstrations, so it can help with everyday tasks, and emulate human movement just by observing us.


- this is made possible with NVIDIA’s technologies, that can understand humans from videos, train models and simulation, and ultimately deploy them directly to physical robots.

- connecting group to a large language model.

- even allows it to generate motions by following natural language instructions.
- hi GL1 can you give me a high five.
- sure thing let’s high five.

- can you give us some cool moves.
- sure check this out.

- all this incredible intelligence is powered by the new Jetson Thor robotics chips, designed for GR00T, built for the future.
- with Isaac Lab, OSMO, and GR00T we’re providing the building blocks for the next generation of AI powered robotics.
Wrap Up
Robots on the Stage
- about the same size.


- the soul of NVIDIA, the intersection of computer graphics, physics, artificial intelligence, it all came to bear at this moment.
- the name of that Project General Robotics 003.
- I know, super good.
- super good.
- well I think we have some special guests.
- do we.
- hey guys.
- so I understand you guys are powered by Jetson.
- they’re powered by Jetson.
- little Jetson robotics computers inside.
- they learn to walk in Isaac Sim.
- ladies and gentlemen, this this is orange, and this is the famous green.
- they are the BDX robots of Disney.

- amazing Disney research.
- come on you guys let’s wrap up.

- let’s go.
- five things.
- where you going.
- I sit right here.
- Don’t Be afraid.
- come here green hurry up.
- what are you saying.
- no it’s not time to eat.
- it’s not time.
- to I’ll I’ll give you a snack in a moment.
- let me finish up real quick.
- come on green hurry up.
- stop wasting time.
- five things, five things.

1 - Accelerated Computing
- first a new Industrial Revolution.
- every data center should be accelerated.
- a trillion dollars worth of installed data centers.
- will become modernized over the next several years.
- second because of the computational capability we brought to bear.
- a new way of doing software has emerged.
- generative AI which is going to create new in new infrastructure, dedicated to doing one thing and one thing only, not for multi-user data centers, but AI generators.
- these AI generation will create incredibly valuable software.
- a new Industrial Revolution.
2 - Blackwell
- second the computer of this revolution the computer of this generation, generative AI trillion parameters Blackwell insane amounts of computers and computing.
- third I’m trying to concentrate.
- good job.
3 - NIMs
- third new computer new computer creates new types of software new type of software should be distributed in a new way.
- so that it can on the one hand be an endpoint in the cloud and easy to use, but still allow you to take it with you, because it is your intelligence, your intelligence should be pack packaged up in a way that allows you to take it with you.
- we call them NIMs.
- and third these NIMs are going to help you create a new type of application for the future.
- not one that you wrote completely from scratch.
- but you’re going to integrate them.
4 - NeMo and AI Foundry
- like teams create these applications we have a fantastic capability between NIMs the AI technology the tools NeMo and the infrastructure DGX Cloud in our AI Foundry to help you create proprietary applications, proprietary chatbots.
5 - Omniverse and Isaac Robotics
- and then lastly everything that moves in the future will be robotic, you’re not going to be the only one.
- and these robotic systems whether they are humanoid, amrs, self-driving cars forklifts manipulating arms they will all need one thing, giant stadiums, warehouses, factories there can to be factories that are robotic orchestrating factories uh manufacturing lines that are robotics building cars that are robotics.
- these systems all need one thing, they need a platform a digital platform, a digital twin platform, and we call that Omniverse, the operating system of the robotics world.
- these are the five things that we talked about today.
- what does NVIDIA look like.
- what does NVIDIA look like.
- when we talk about GPUs.
- there’s a very different image that I have when I when people ask me about GPUs.
- first I see a bunch of software stacks and things like that, and second I see this, this is what we announce to you today this is Blackwell.
- this is the plat amazing amazing processors, NVLink switches, networking systems, and the system design is a miracle.
- this is Blackwell.
- and this to me is what a GPU looks like in my mind.

- listen orange, green, I think we have one more treat for everybody.
- what do you think should we.
Wrap-up Video
- okay.
- we have one more thing to show you.
- roll it.














- thank you.
- thank you have a great have a great GTC.

- thank you all for coming.
- thank you.
Reference
In radio, multiple-input and multiple-output (MIMO) (/ˈmaɪmoʊ, ˈmiːmoʊ/) is a method for multiplying the capacity of a radio link using multiple transmission and receiving antennas to exploit multipath propagation. - MIMO - Wikipedia ↩︎
CUDA Toolkit - Free Tools and Training | NVIDIA Developer ↩︎
The world’s first ever NVIDIA DGX H200 hand-delivered to OpenAI by the GPU king himself, Jensen Huang. by Farhan Hussain ↩︎
Revolutionary Cadence Reality Digital Twin Platform to Transform Data Center Design for the AI Era | Cadence ↩︎
cuLitho - Accelerate Computational Lithography | NVIDIA Developer ↩︎
From EDA to SDA – The Emergence of Intelligent System Design Automation - Computational Fluid Dynamics - Cadence Blogs - Cadence Community ↩︎
Cadence Unveils Millennium Platform—Industry’s First Accelerated Digital Twin Delivering Unprecedented Performance and Energy Efficiency | Cadence ↩︎
InfiniBand originated in 1999 from the merger of two competing designs: Future I/O and Next Generation I/O (NGIO). NGIO was led by Intel, with a specification released in 1998, and joined by Sun Microsystems and Dell. Future I/O was backed by Compaq, IBM, and Hewlett-Packard. This led to the formation of the InfiniBand Trade Association (IBTA). - InfiniBand - Wikipedia ↩︎
Selene is a supercomputer developed by Nvidia, capable of achieving 63.460 petaflops, ranking as the fifth fastest supercomputer in the world, when it entered the list. Selene is based on the Nvidia DGX system consisting of AMD CPUs, Nvidia A100 GPUs, and Mellanox HDDR networking. - Selene (supercomputer) - Wikipedia ↩︎
Eos is built with 576 NVIDIA DGX H100 systems, NVIDIA Quantum-2 InfiniBand networking and software, providing a total of 18.4 exaflops of FP8 AI performance. - NVIDIA Eos Revealed: Peek Into Operations of a Top 10 Supercomputer | NVIDIA Blog ↩︎
The Nvidia Hopper H100 GPU is implemented using the TSMC 4N process with 80 billion transistors. It consists of up to 144 streaming multiprocessors. In SXM5, the Nvidia Hopper H100 offers better performance than PCIe. The Nvidia Hopper H100 supports HBM3 and HBM2e memory up to 80 GB; the HBM3 memory system supports 3 TB/s, an increase of 50% over the Nvidia Ampere A100’s 2 TB/s. Across the architecture, the L2 cache capacity and bandwidth were increased. - Hopper (microarchitecture) - Wikipedia ↩︎
NVLink is a wire-based serial multi-lane near-range communications link developed by Nvidia. Unlike PCI Express, a device can consist of multiple NVLinks, and devices use mesh networking to communicate instead of a central hub. The protocol was first announced in March 2014 and uses a proprietary high-speed signaling interconnect (NVHS). - NVLink - Wikipedia ↩︎
PCI Express (Peripheral Component Interconnect Express), officially abbreviated as PCIe or PCI-e, is a high-speed serial computer expansion bus standard, designed to replace the older PCI, PCI-X and AGP bus standards. It is the common motherboard interface for personal computers’ graphics cards, sound cards, hard disk drive host adapters, SSDs, Wi-Fi and Ethernet hardware connections. - PCI Express - Wikipedia ↩︎
NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference | NVIDIA Technical Blog ↩︎