
(Photo by Christian De Stradis on Unsplash)
Briefing
Amazon Kinesis has four capabilities:
- Kinesis Video Streams (KVS),
- Kinesis Data Streams (KDS),
- Kinesis Data Firehose (KDF), and
- Kinesis Data Analytics (KDA) 👉 Amazon Managed Service for Apache Flink.
The one-sentence description of each of them in the official document says:
- Amazon Kinesis Video Streams (KVS)
- Capture, process, and store video streams for analytics and machine learning.
- Amazon Kinesis Data Streams (KDS)
- Build custom applications that analyze data streams using popular stream-processing frameworks.
- Amazon Kinesis Data Firehose (KDF)
- Load data streams into AWS data stores.
- Amazon Kinesis Data Analytics (KDA) 👉 Amazon Managed Service for Apache Flink
- Process and analyze streaming data using SQL or Java.
History
From ancient to modern times. Get through all the context.
- 2023-0830: Announcing Amazon Managed Service for Apache Flink Renamed from Amazon Kinesis Data Analytics.
Terms
Here is a list of nouns that appear on the scene, and the full name of the original text, noun definition and source are noted.
Amazon Kinesis Data Streams (KDS)
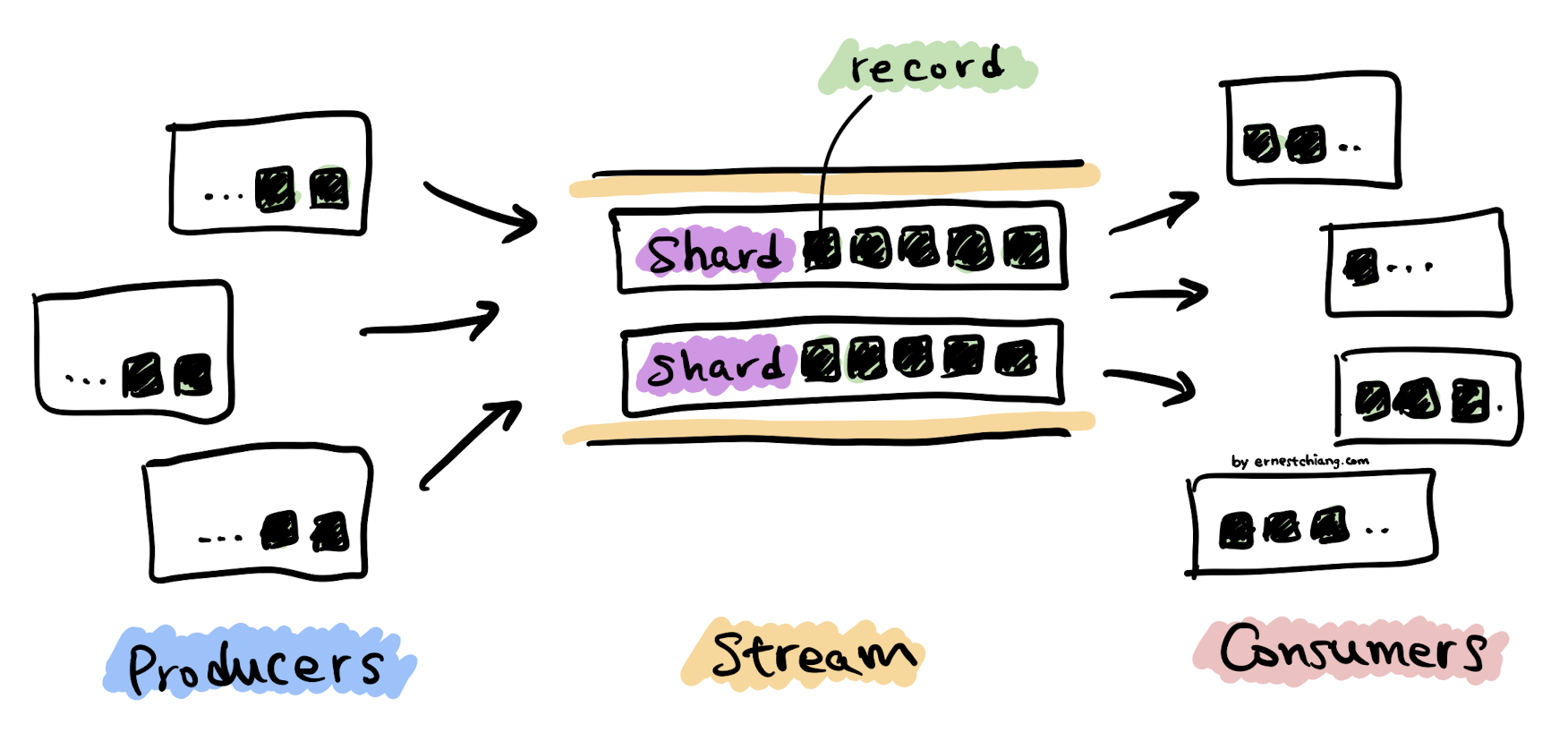
(Amazon Kinesis Data Streams High-Level Architecture)
Kinesis Data Stream
- A Kinesis data stream is a set of shards.
- Each shard has a sequence of data records.
- Each data record has a sequence number that is assigned by Kinesis Data Streams.
Data Record
- A data record is the unit of data stored in a Kinesis data stream.
- Data records are composed of a sequence number, a partition key, and a data blob, which is an immutable sequence of bytes.
- A data blob can be up to 1 MB.
Retention Period
- The retention period is the length of time that data records are accessible after they are added to the stream.
- Default: 24 hours
- Minimum: 24 hours (using the DecreaseStreamRetentionPeriod operation.)
- Maximum: 8760 hours (365 days) (using the IncreaseStreamRetentionPeriod operation)
- Additional charges apply for streams with a retention period set to more than 24 hours.
Producer
- Producers put data records into Amazon Kinesis Data Streams.
Consumer
- Consumers get data records from Amazon Kinesis Data Streams.
- Consumers == Amazon Kinesis Data Streams Application (KDS App).
Amazon Kinesis Data Streams Application (KDS App)
- Two types:
- Shared fan-out consumers
- Enhanced fan-out consumers
- Using:
- AWS Lambda
- Kinesis Data Analytics 👉 Amazon Managed Service for Apache Flink
- Kinesis Data Firehose
- Kinesis Client Library
- The output of a KDS app can be input for another stream.
- Docs: Reading Data from Amazon Kinesis Data Streams - Amazon Kinesis Data Streams
Shard
- A shard is a uniquely identified sequence of data records in a stream.
- A stream is composed of one or more shards, each of which provides a fixed unit of capacity.
- Each shard can support
- up to 5 transactions per second for reads,
- up to a maximum total data read rate of 2 MB per second,
- up to 1,000 records per second for writes,
- up to a maximum total data write rate of 1 MB per second (including partition keys).
Partition Key
- A partition key is used to group data by shard within a stream.
- Partition keys are Unicode strings, with a maximum length limit of 256 characters for each key.
- An MD5 hash function is used to map partition keys to 128-bit integer values and to map associated data records to shards using the hash key ranges of the shards.
- When an application puts data into a stream, it must specify a partition key.
Sequence Number
- Each data record has a sequence number that is unique per partition-key within its shard.
- Sequence number is assigned by KDS.
- Sequence numbers cannot be used as indexes to sets of data within the same stream. To logically separate sets of data, use partition keys or create a separate stream for each dataset.
Amazon Kinesis Data Firehose (KDF)
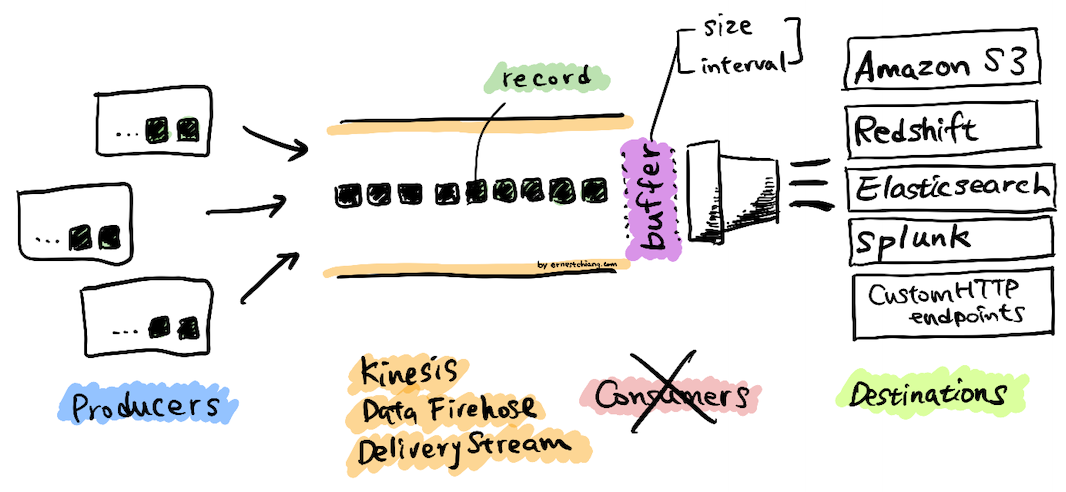
(Amazon Kinesis Data Firehose High-Level Architecture)
Kinesis Data Firehose Delivery Stream
- The underlying entity of Kinesis Data Firehose.
- You use Kinesis Data Firehose by creating a Kinesis Data Firehose delivery stream and then sending data to it.
Data Record
- The data of interest that your data producer sends to a Kinesis Data Firehose delivery stream.
- A record can be as large as 1,000 KB.
Producer
- Producers send records to Kinesis Data Firehose delivery streams.
Buffer Size and Buffer Interval
- Kinesis Data Firehose buffers incoming streaming data to a certain size or for a certain period of time before delivering it to destinations.
- Buffer Size is in MBs and
- Buffer Interval is in seconds.
Amazon Kinesis Data Analytics (KDA) 👉 Amazon Managed Service for Apache Flink
Use Cases
Typical scenarios:
Amazon Kinesis Data Streams (KDS)
- Accelerated log and data feed intake and processing
- Real-time metrics and reporting
- Real-time data analytics
- Complex stream processing (using Directed Acyclic Graphs (DAGs))
Amazon Kinesis Data Analytics (KDA) 👉 Amazon Managed Service for Apache Flink
Amazon Kinesis Data Analytics enables you to quickly author SQL code that continuously reads, processes, and stores data in near real time.
- Generate time-series analytics
- Feed real-time dashboards
- Create real-time metrics
Frequently Information
KDS Getting Started
Docs: Perform Basic Kinesis Data Stream Operations Using the AWS CLI - Amazon Kinesis Data Streams
- Step 1: Create a Stream
- Create:
aws kinesis create-stream --stream-name Foo --shard-count 1 - Check:
aws kinesis describe-stream-summary --stream-name Foo - CREATING –> ACTIVE
- Double check:
aws kinesis list-streams
- Create:
- Step 2: Put a Record
aws kinesis put-record --stream-name Foo --partition-key 123 --data testdata
- Step 3: Get the Record
- Step 3.1: GetShardIterator
- Before you can get data from the stream you need to obtain the shard iterator for the shard you are interested in.
aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Foo
- Step 3.2: GetRecords
aws kinesis get-records --shard-iterator AAAAAAAAAAHSywljv0zEgPX4NyKdZ5wryMzP9yALs8NeKbUjp1IxtZs1Sp+KEd9I6AJ9ZG4lNR1EMi+9Md/nHvtLyxpfhEzYvkTZ4D9DQVz/mBYWRO6OTZRKnW9gd+efGN2aHFdkH1rJl4BL9Wyrk+ghYG22D2T1Da2EyNSH1+LAbK33gQweTJADBdyMwlo5r6PqcP2dzhg=- Data needs Base64 decoding.
- UNIX-like OS:
SHARD_ITERATOR=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Foo --query 'ShardIterator')aws kinesis get-records --shard-iterator $SHARD_ITERATOR
- Step 3.1: GetShardIterator
- Step 4: Clean Up
aws kinesis delete-stream --stream-name Fooaws kinesis describe-stream-summary --stream-name Foo
Deep Dive
The general direction is a path, but beware of pits on the ground.
Concurrrency - Producer/Consumer Pattern
- Lecture: Concurrency—Producer/Consumer Pattern and Thread Pools
- The Producer Consumer Pattern described in Java Concurrency and Multithreading Tutorial by Jakob Jenkov.
- Producer–consumer problem - Wikipedia
Amazon Kinesis Data Streams (KDS) vs. Amazon SQS
Comparison table.
| Product | Amazon Kinesis Data Stream | Amazon SQS |
|---|---|---|
| Essential | Streaming service | Messaging service |
| Use Cases | - Log and event data collection - Real-time analytics - Mobile app event data feed - IoT data feed | - Application integration - Decouple microservices - Scale jobs to multiple workers |
| Scaling | Manually increase/decrease shards | AWS fully-managed |
| Durability | Deleted on expiry, or up to reach max retention period. | Deleted by consumer, or up to reach max retention period. |
| Default Retention Period | 24 hours | 4 days |
| Min Retention Period | 24 hours | 60 seconds |
| Max Retention Period | 8760 hours (365 days) | 1,209,600 seconds (14 days) |
| Message Order | Ordered within the shard | Standard - Best effort FIFO - Ordered within the message group |
| Message Size | 1MB | 256KB |
| Message Replay | Yes | No |
| Message Consume | Consumers can read the same data records | One message can be consumed by only one consumer at a time |
Amazon Kinesis Data Streams (KDS) vs. Amazon Kinesis Data Firehose (KDF)
Comparison table.
| Product | Amazon Kinesis Data Stream | Amazon Kinesis Data Firehose |
|---|---|---|
| Essential | Streaming service | Delivering streaming data to destinations |
| Scaling | Manually increase/decrease shards | AWS fully-managed |
| How real time? | Real time (200ms for classic, 70ms for enhanced fan-out) | Near real time (lowest buffer time is 60 seconds) |
| Message Storage | 24~8760 hours | No data storage |
| Message Replay | Yes | No |
| Message Producer | Using KPL, SDK (API), Kinesis Agent (on Amazon Linux, or RHE) | Kinesis Data Streams, Kinesis Agent, SDK, CloudWatch Logs, CloudWatch Events, AWS IoT |
| Message Consumer | Using KCL, SDK (API), AWS Lambda, Kinesis Data Analytics, Kinesis Data Firehose. Can be multiple consumers. | Managed by Kinesis Data Firehose (You have decided destination when you create Kinesis Data Firehose Delivery Stream.) |
| Message Transformation | (Handled by your consumers.) | Serverless data transformations with AWS Lambda |
| Message Destination | Multiple destinations. (Handled by your consumers.) | Amazon S3, Amazon Redshift, Amazon ES, Splunk, and any custom HTTP endpoint, or HTTP endpoints owned by supported third-party service providers. |
Reference
Examples
- Tutorial: Using AWS Lambda with Amazon Kinesis Data Streams (Official docs)
- AWS Streaming Data Solution for Amazon Kinesis (Official reference design)
- Combining content moderation services with graph databases & analytics to reduce community toxicity, 2023-09-14, by Andrew Thomas